PyCon China 上海2015
中文搜索经验分享
Esc to overview
← → to navigate

Liang Bo Wang (亮亮), 2015-09-14
繁体完整版本
Esc to overview
← → to navigate
 用 ElasticSearch (ES) 做站上商品的搜索
用 ElasticSearch (ES) 做站上商品的搜索


实际上座标空间有 V 维,这个可以想成映射在某个平面空间时
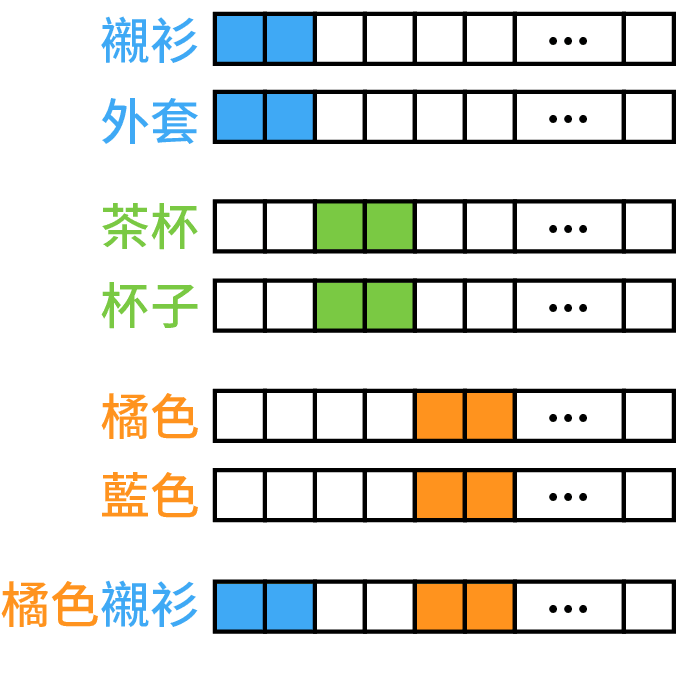
注:这是很理想的状况,现实中可能不会这么理想,相加的概念会被高频的单字 dominate。例如「○○茶」基本上就是「茶」,除非○○的词频够足以让 word2vec 的矢量够明确,例如「高山茶」就能与「茶」有所区别;像「伯爵茶」的「伯爵」概念就会被实际的「伯爵」所影响。
这时候就需要更精细的断词系统。
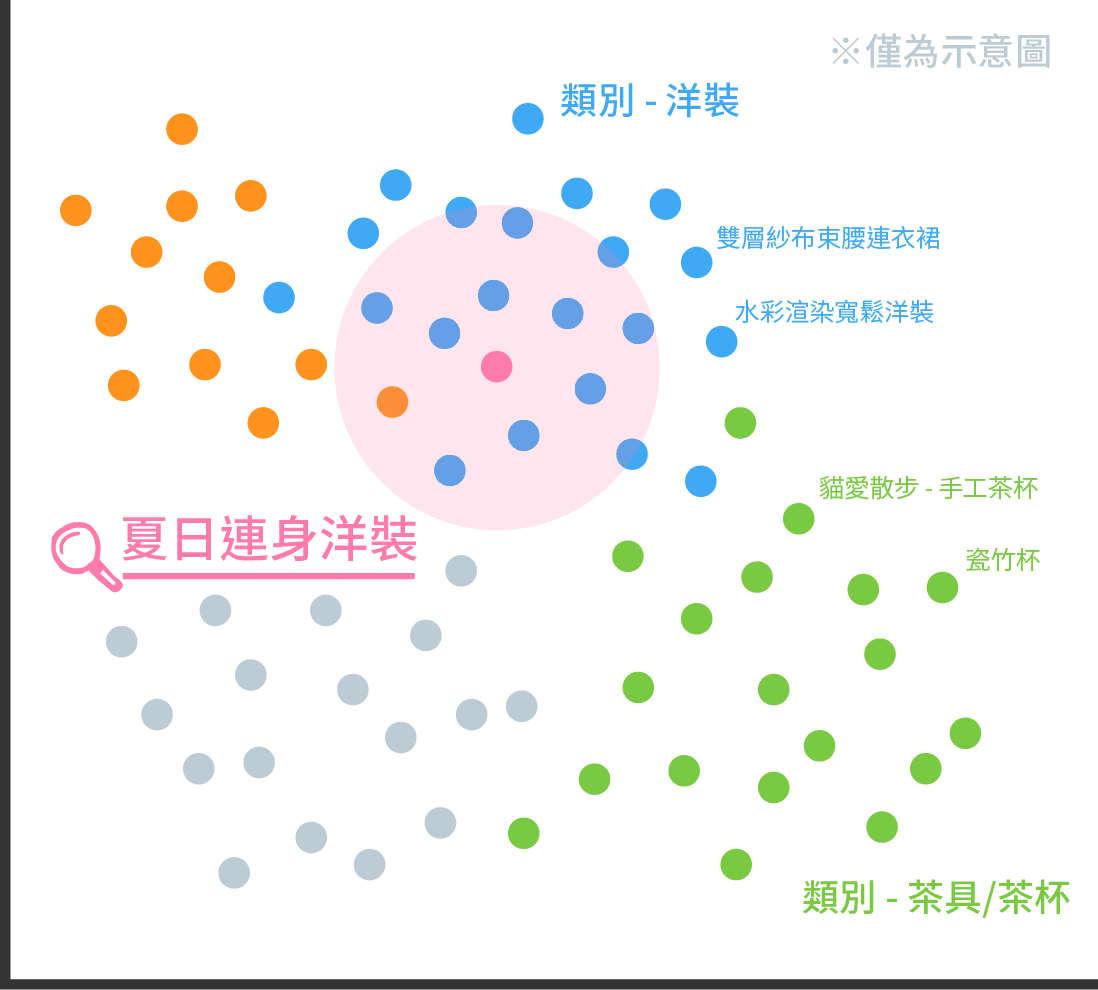
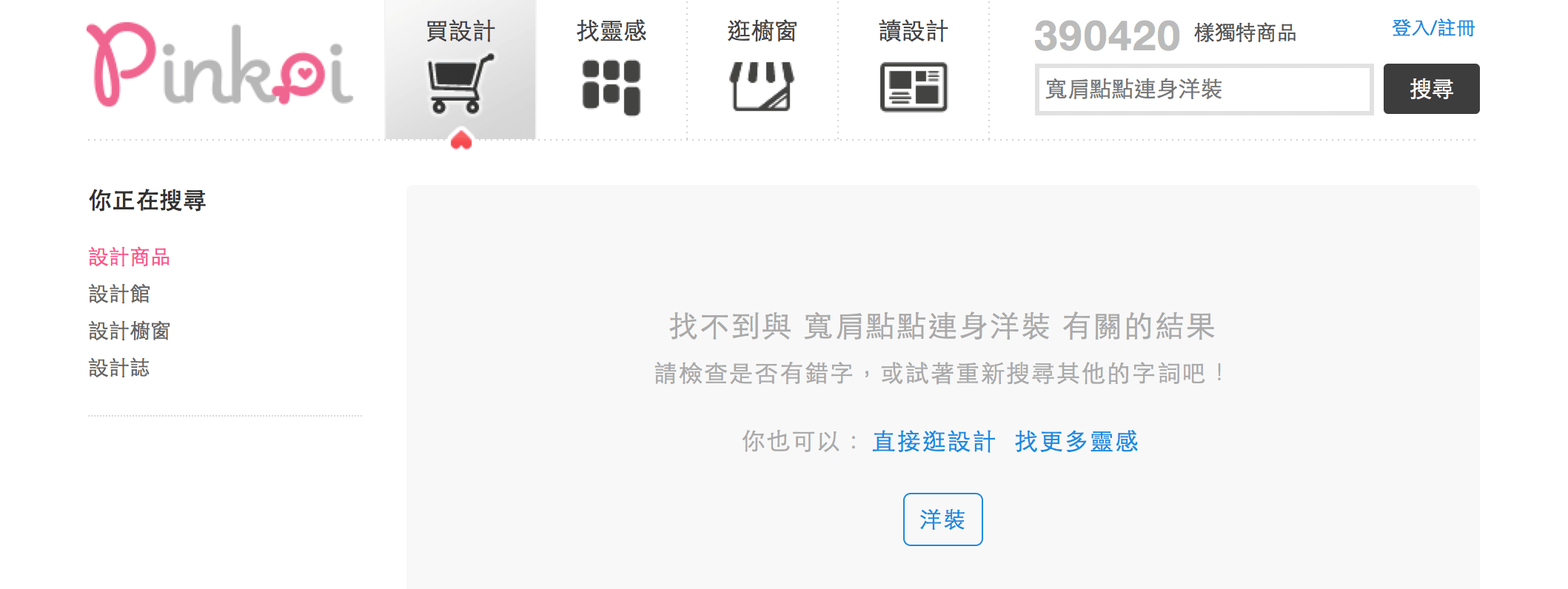
🔍 宽肩点点连身洋装
?我们关心并努力改善来自各地的用户体验
 is hiring
is hiringBack-End | QA | Data | Search
Front-End | iOS | Android