MLDM Monday, 2015-09-14
中文搜尋經驗分享
Esc to overview
← → to navigate

Liang Bo Wang (亮亮), 2015-09-14
Esc to overview
← → to navigate

 用 ElasticSearch (ES) 做站上商品的搜尋
用 ElasticSearch (ES) 做站上商品的搜尋




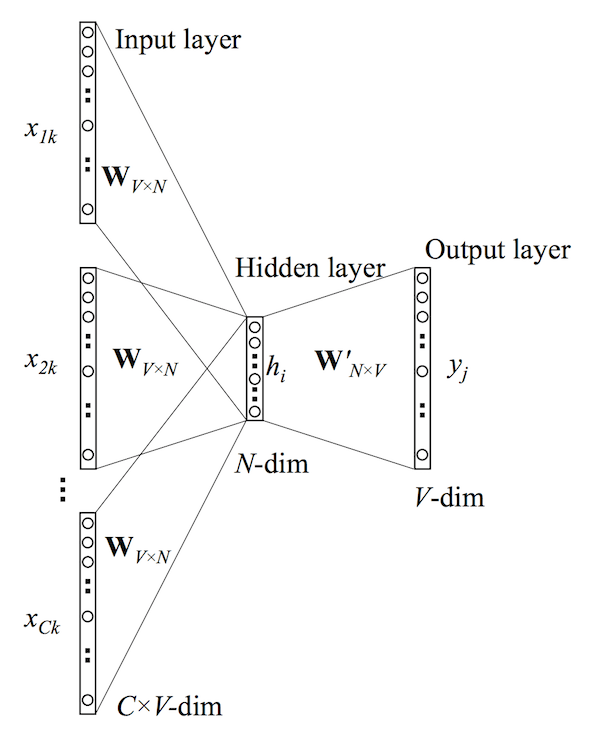
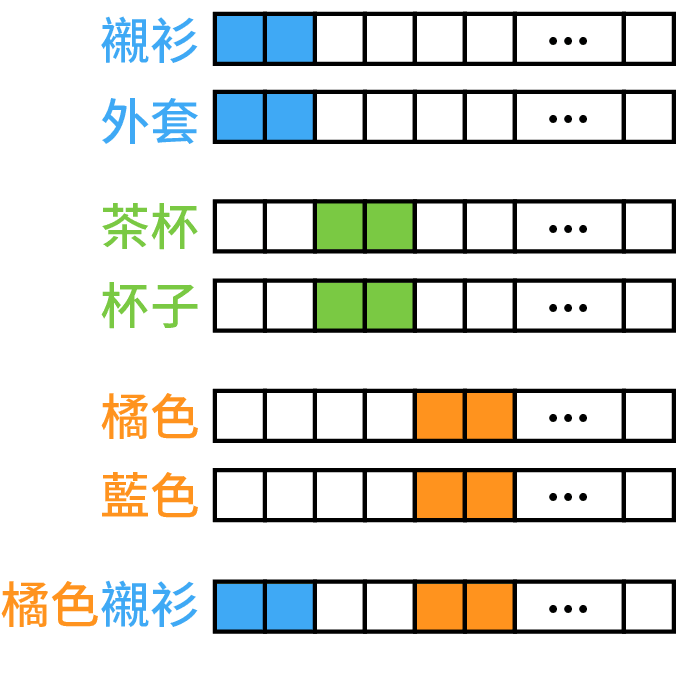
實際上座標空間有 V 維,這個可以想成映射在某個平面空間時
註:這是很理想的狀況,現實中可能不會這麼理想,相加的概念會被高頻的單字 dominate。例如「○○茶」基本上就是「茶」,除非○○的詞頻夠足以讓 word2vec 的向量夠明確,例如「高山茶」就能與「茶」有所區別;像「伯爵茶」的「伯爵」概念就會被實際的「伯爵」所影響。
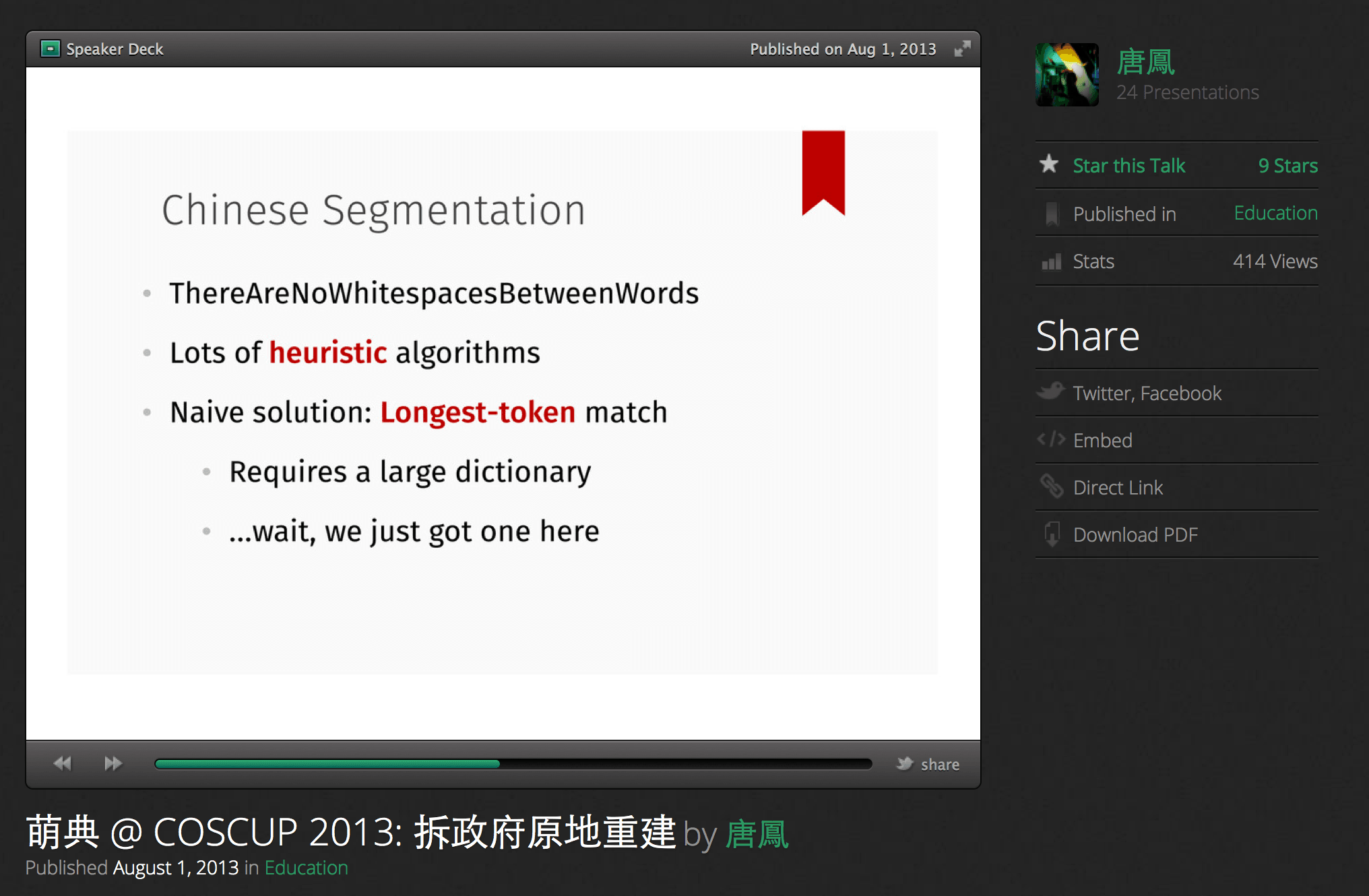
這時候就需要更精細的斷詞系統。
還有一些很有趣的特性
\[ \begin{align*} &m_{東京} - m_{日本} \\ \approx& m_{柏林} - m_{德國} \end{align*} \]
因為維基的敘述像「東京是日本的首都」、「柏林是德國的首都」
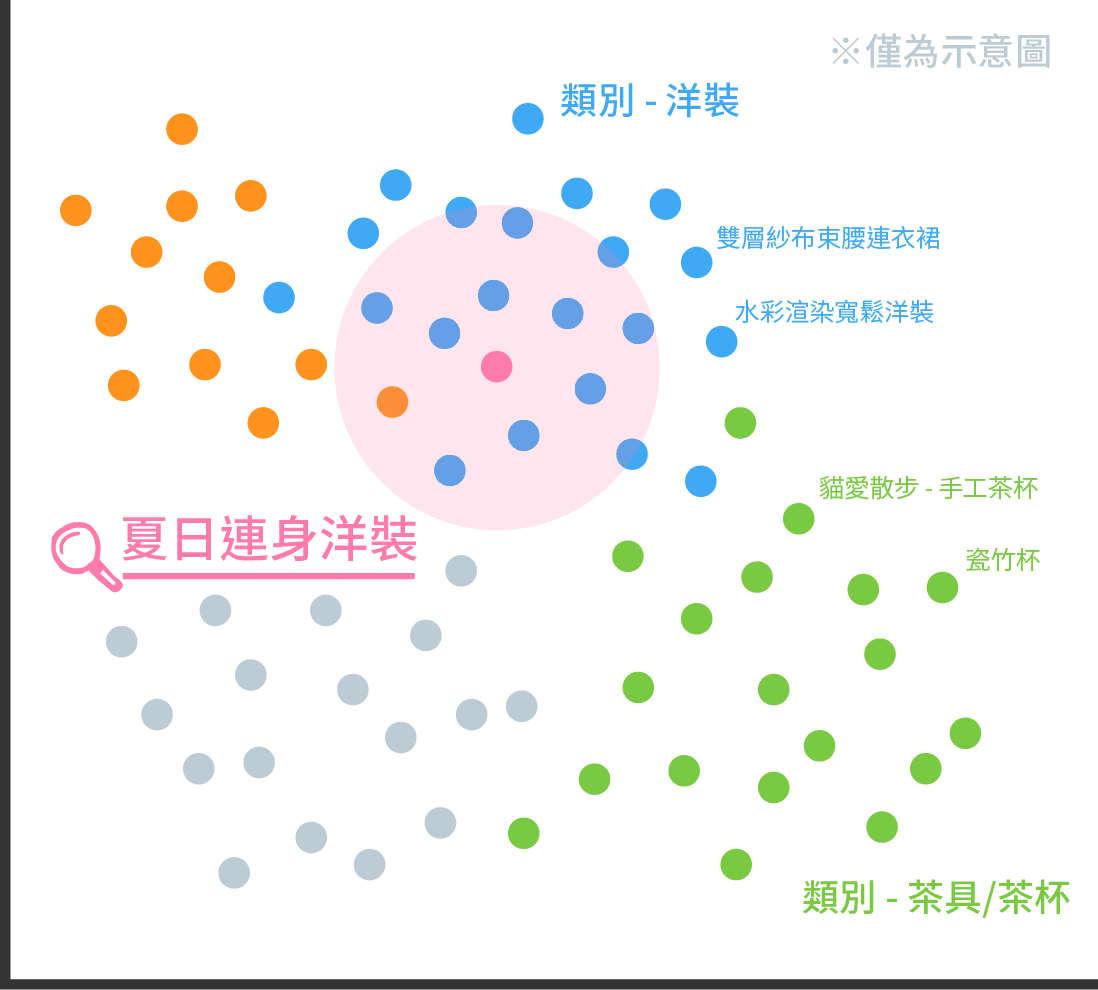
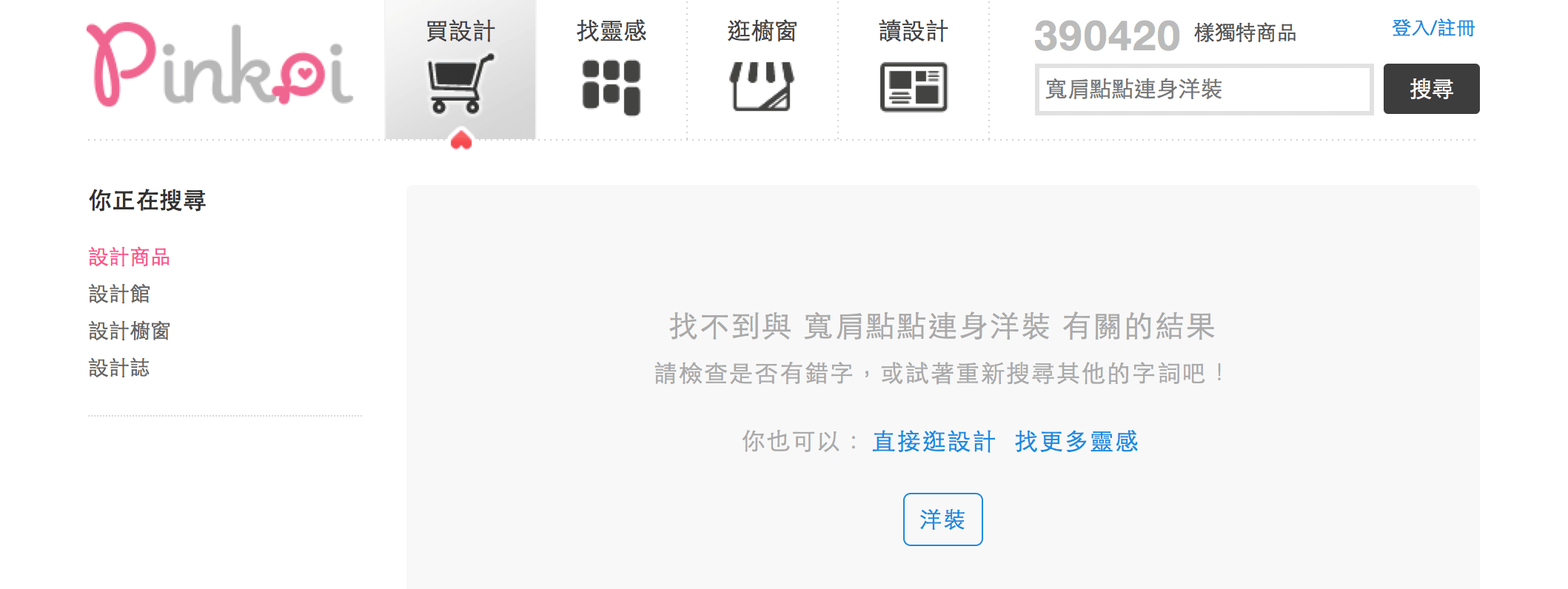
🔍 寬肩點點連身洋裝
?我們關心並努力改善來自各地的使用者體驗
 is hiring
is hiringBack-End | QA | Data | Search
Front-End | iOS | Android

以下言論不代表
公司立場 XD