範例要從一個浪漫的故事說起……
一個男生開著車,在一個暴風雨的晚上。
經過一個車站,三人正焦急的等公車。一位是需要急救的老人;另外一位是醫生,他正在照顧那位老人;
最後一位則是他的夢中情人。但男生的車只能再坐一個人。
Liang Bo Wang, 2013-11-16
Liang Bo Wang、 線上版投影片 Under CC 3.0 BY TW License

pic source: http://seuconteudonaweb.wordpress.com/2013/08/06/a-big-analise-de-dados/

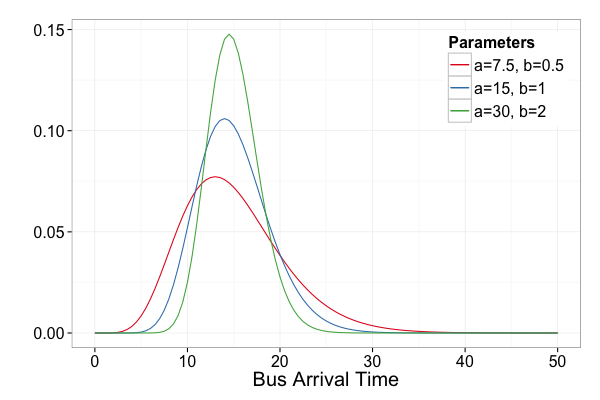
$$T \sim Gamma(a, b)$$
Gamma 分配有以下特性: $$ E[T] = \frac{a}{b}, ~ Var[T] = \frac{E[T]}{b}$$
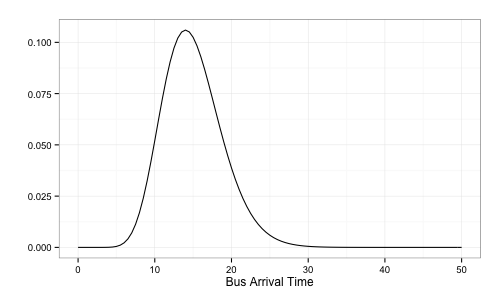
假設公車 15 分鐘來一班,則 $$a=15, b=1$$
bus.gamma <- function(t) dgamma(t, 15, 1)
curve(bus.gamma, from=0, to=50)
為何不用 \(a = 7.5, b = 0.5\) ?
公車超過 18 分鐘才來的機率? $$ P(T > 18) = 1 - P(T \leq 18) $$
1 - pgamma(18, 15, 1)
# 0.208 橘色區域
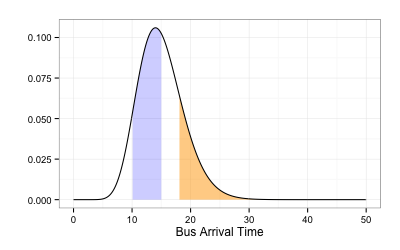
公車 10 - 15 分鐘來的機率? $$\begin{align} &P(10 < T \leq 15) \\ = &P(T \leq 15) - P(T \leq 10) \end{align}$$
pgamma(15, 15, 1) -
pgamma(10, 15, 1)
# 可以更簡潔寫成
diff(pgamma(c(10, 15), 15, 1))
# 0.451 藍色區域
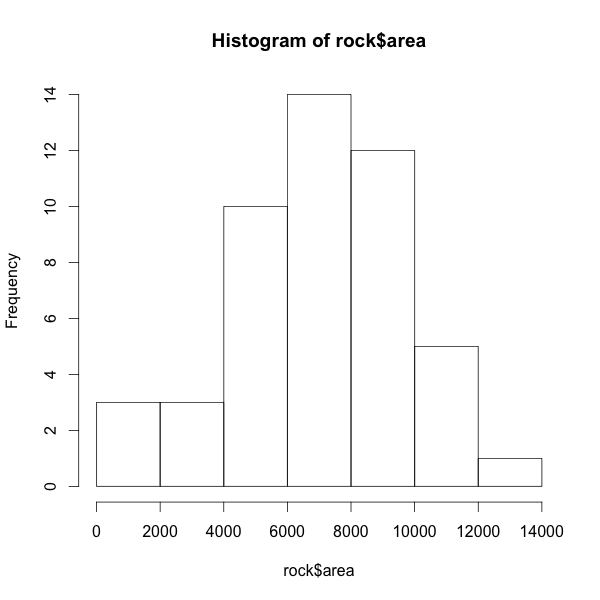
手邊沒有資料玩的話,data() 查詢內建的 datasets
以 rock 為例,
hist(rock$area)
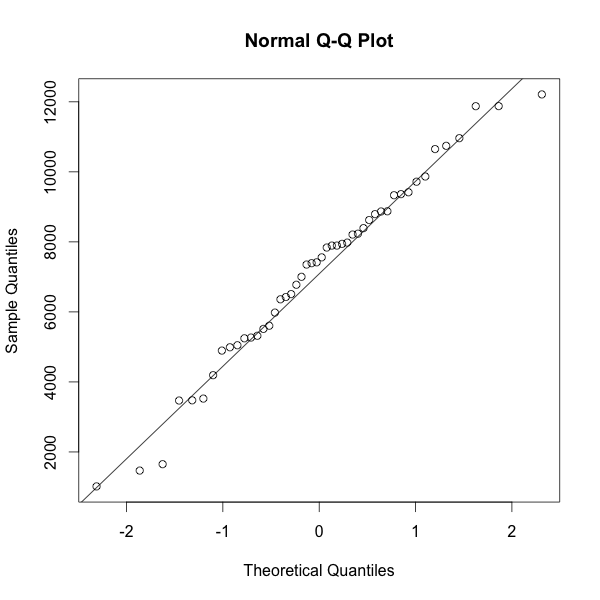
查看抽樣的分布
選擇常態分布,適不適合?
qqnorm(rock$area)
# or qqplot
qqline(rock$area)
我們學會了估計一個機率分布(點估計)。
如果今天是區分兩組資料的平均值是不是「不一樣」…
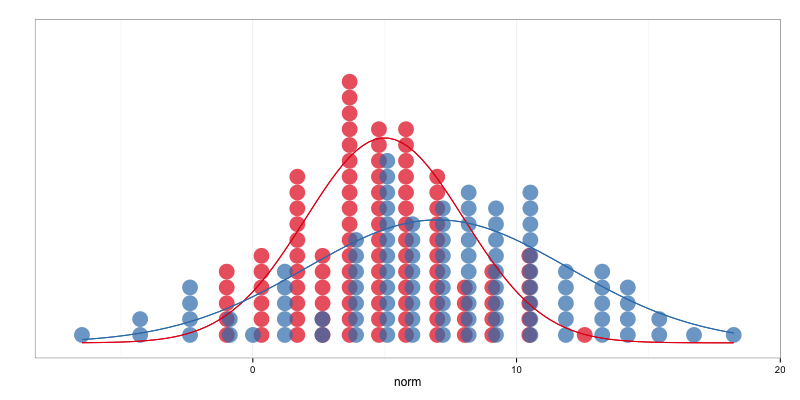
這組蠻好判斷的
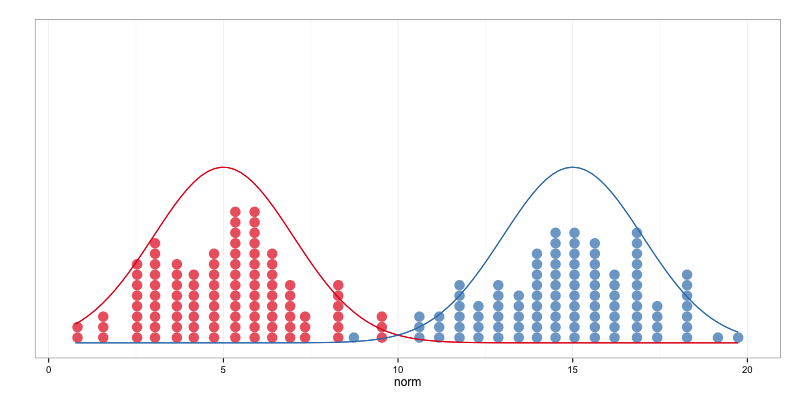
那這組呢?