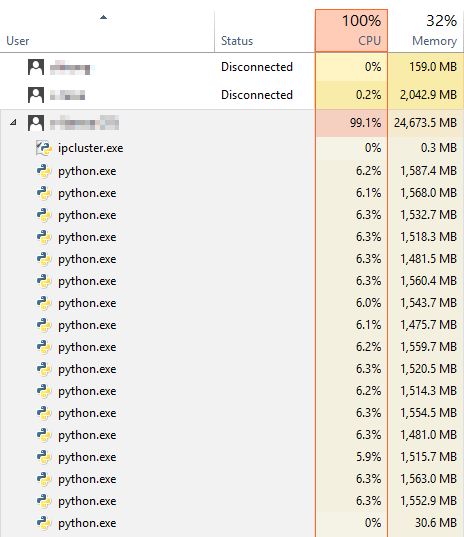
Aweful feelings ...
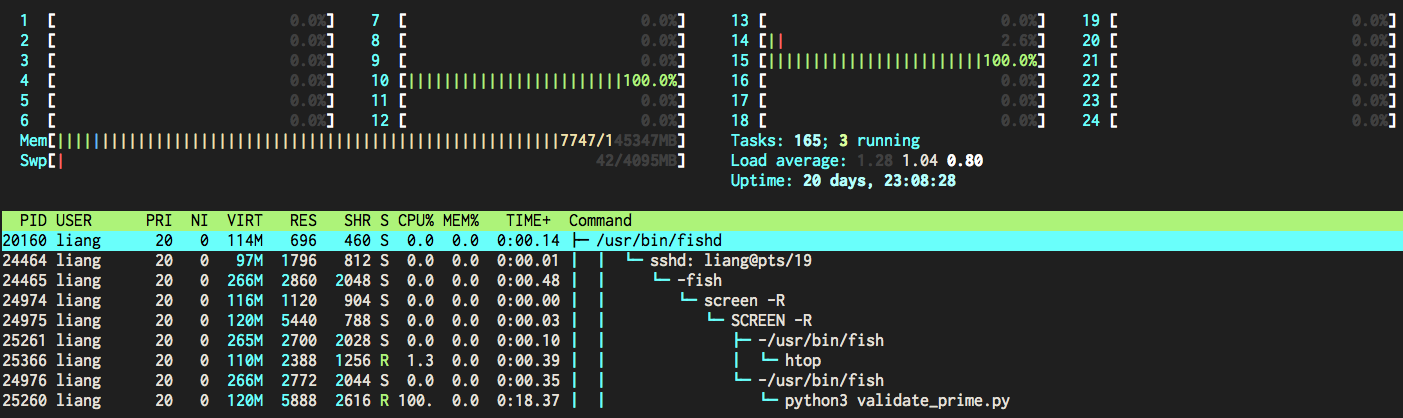
Engineers' time is more valuable than computing, but many algorithms is hard to make it parallel.
Liang Bo Wang (亮亮), 2015-04-27
Esc to overview
← → to navigate


Engineers' time is more valuable than computing, but many algorithms is hard to make it parallel.
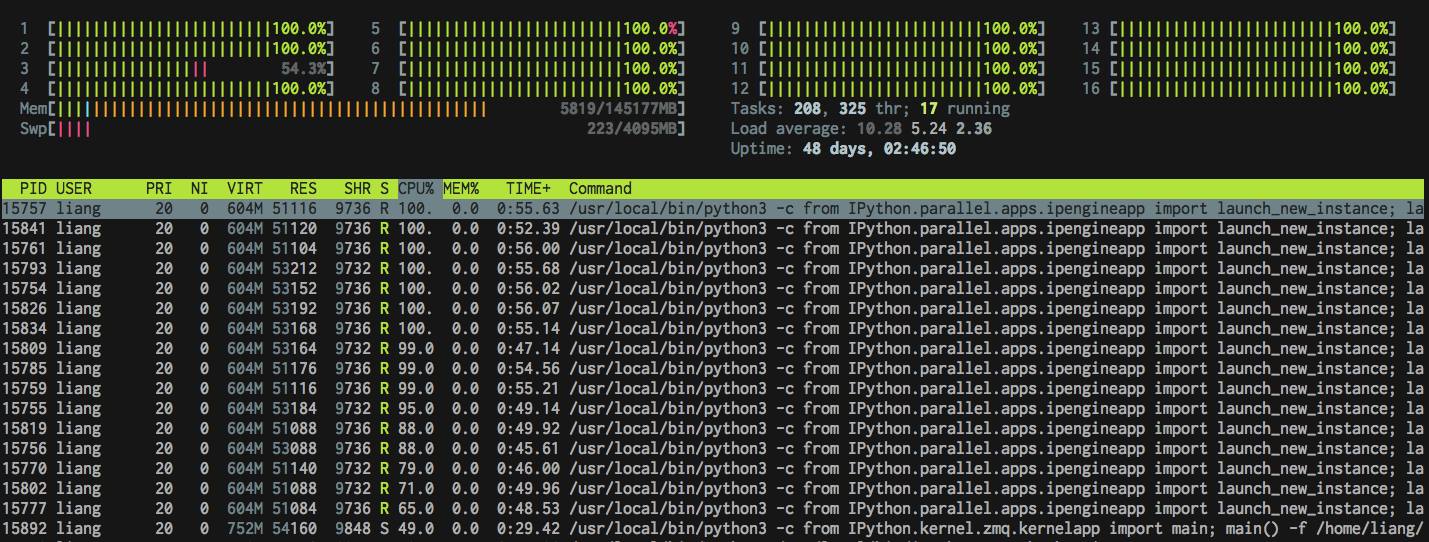
Not hard to implement if your tasks are independent. Here we focus on the easiest pattern:
Apply same program on a bunch of input.

Multithread, threading, does not work as expected because of GIL.
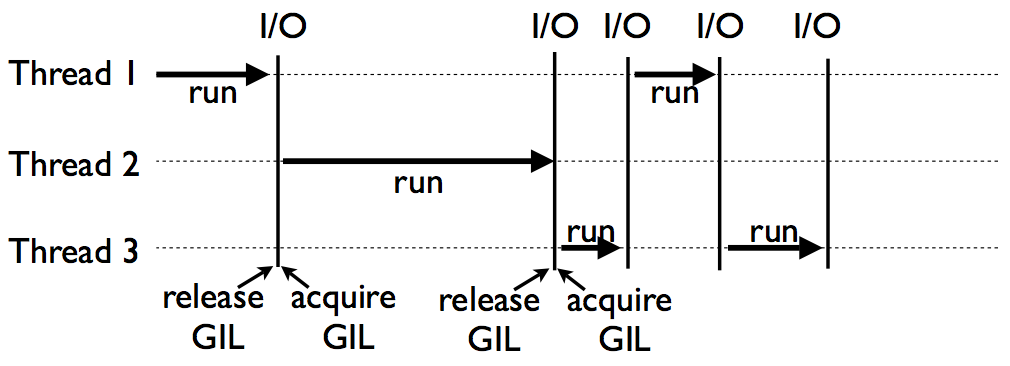 (From David Beazley's Understanding GIL)
(From David Beazley's Understanding GIL)
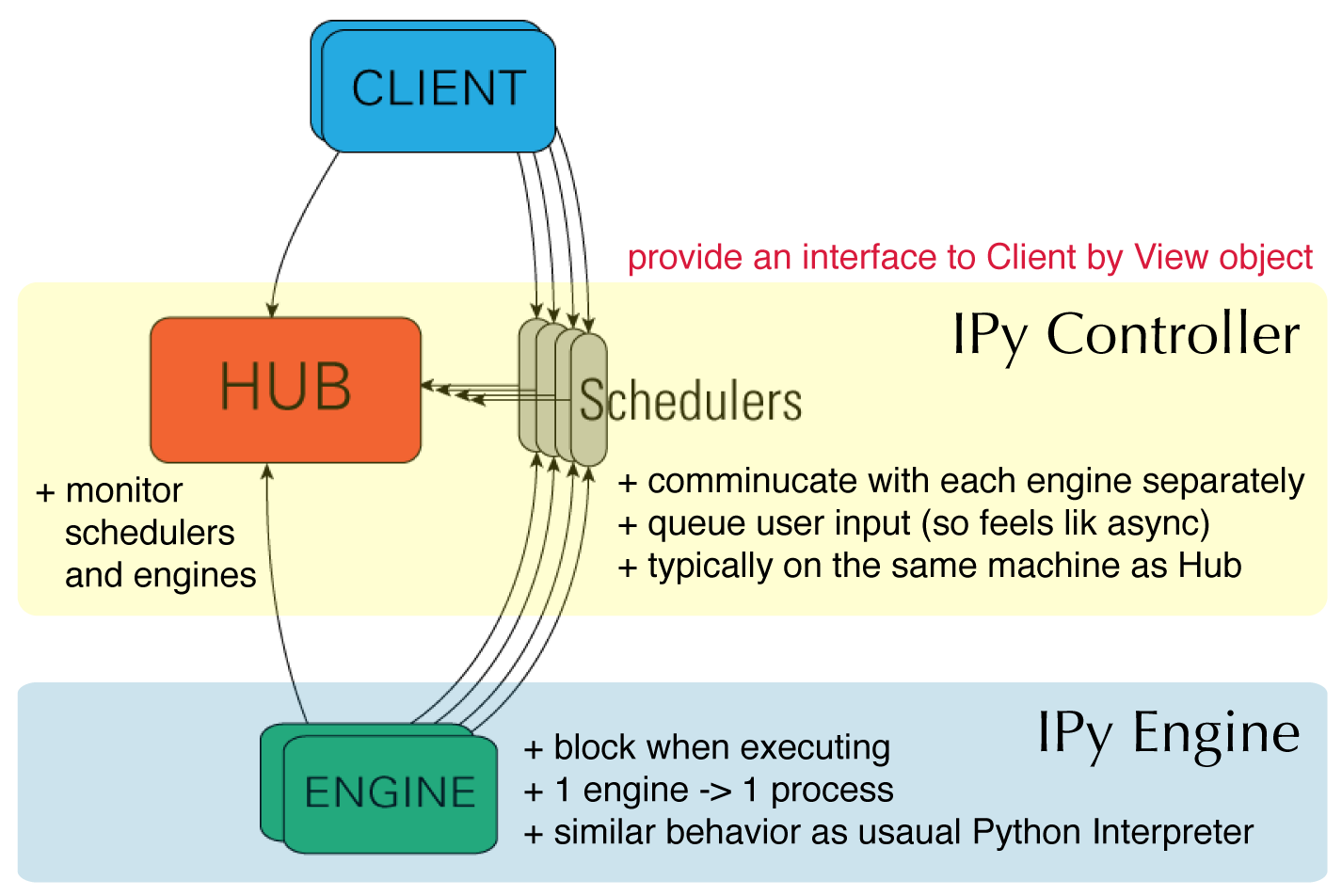
In [1]: from IPython.parallel import Client
...: rc = Client() # connect controller
In [2]: dview = rc[:] # return a View
Adapted from the official docs
$ ipcluster start
# [IPClusterStart] Using existing profile dir: '.../profile_default'
# [IPClusterStart] Starting ipcluster with [daemon=False]
# ... (automatically set up controller and engines locally)
Or use IPython Notebook to start

A deliberate worst case for preallocated task.
Optimally should only take around 3 seconds.

Note the space between adjacent tasks.
If tasks of different engines complete at the same time, they stocked at the load balancer so a longer pause required. (see randomized work for comparison)

All engines run the exactly same number of tasks (shown by color)

Some engines run fewer tasks if their previous work load are heavier. Pause space are shorter since they return randomly.