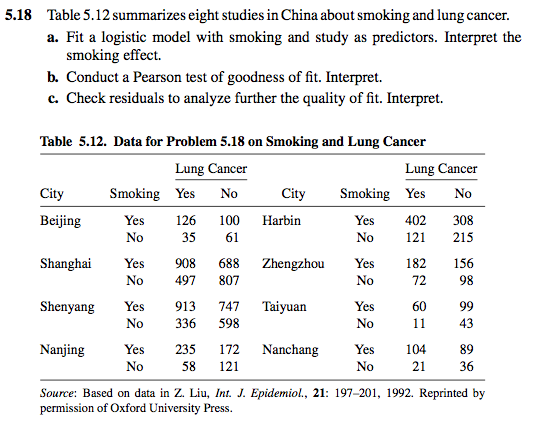
Esc to overview
← → to navigate


從哪裡開始,從哪裡結束。


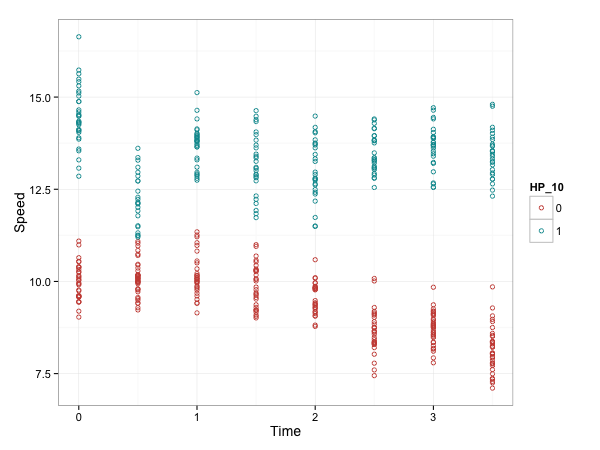
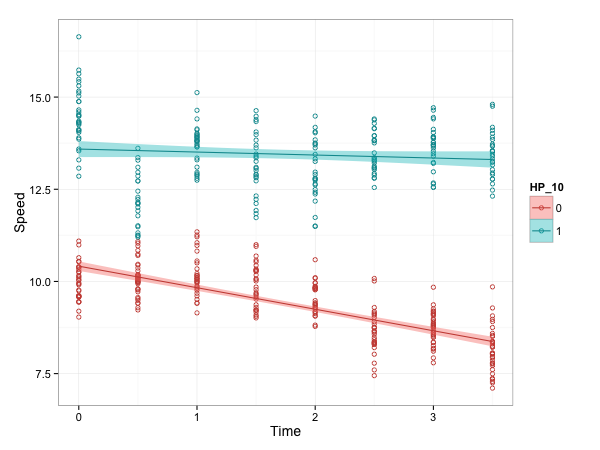
y ~ x使用 stat_smooth()
stat_smooth(
method="lm", formula = y ~ x + I(x^2),
se=FALSE) # use y and x in formula
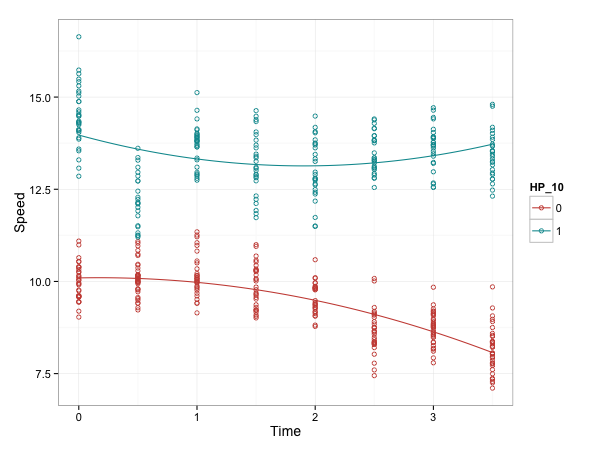
g + geom_point(shape=1) + stat_smooth(
method="glm", family=gaussian(link="inverse"),
formula = y ~ x + I(x^2), se=FALSE)
控制不同城市後,肺癌在有無吸煙人的發生率是不是相同?