Taiwan R User Group, 2015-05-18
Convolutional Neural Network (CNN) From the Ground Up
Esc to overview
← → to navigate

Liang Bo Wang (亮亮), 2015-05-18
Esc to overview
← → to navigate


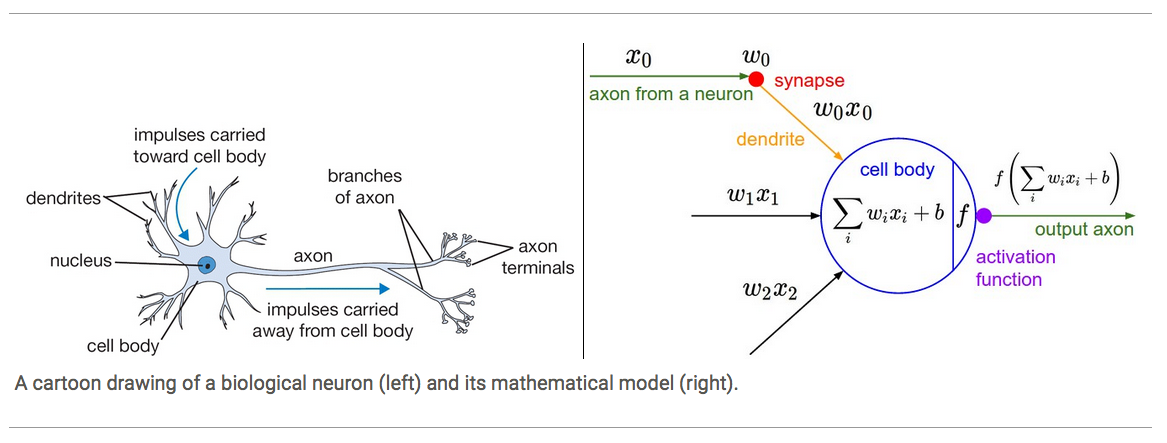
We model the neuron by two parts: linear combination \(\sum w_i x_i\) and activation function \(f\)
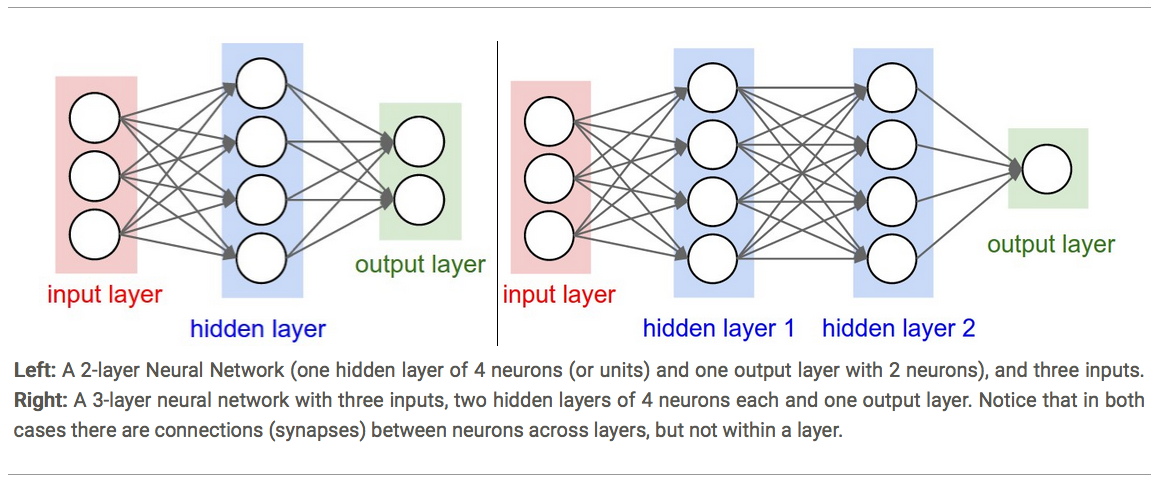
Total size of parameters (weights and biases) [input x #neuron]:
Left is (3 + 1) x 4 + (4 + 1) x 2 = 26.
Right is (3 + 1) x 4 + (4 + 1) x 4 + (4 + 1) x 1 = 41.
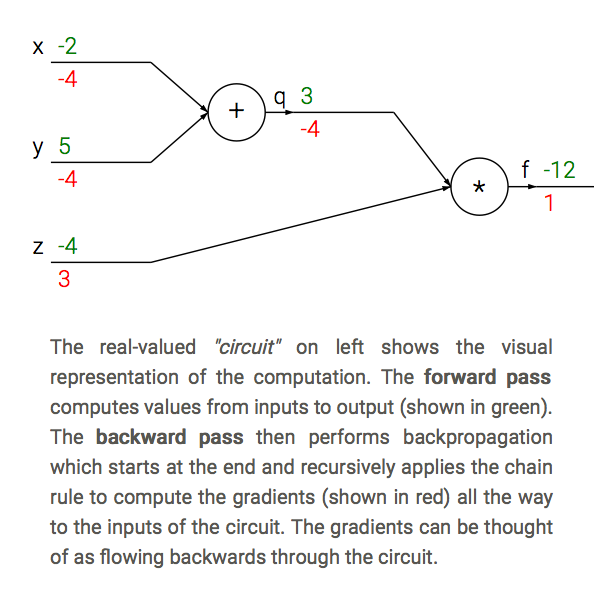
$$ \begin{aligned} f(x, y, z) = (x + y) z \\ q = x + y, \enspace f = qz \end{aligned} $$ $$ \begin{aligned} \Rightarrow \frac{\partial q}{\partial x} &= \frac{\partial q}{\partial y} = 1 \end{aligned} $$ $$ \begin{aligned} \Rightarrow \frac{\partial f}{\partial x} &= \frac{\partial f}{\partial q}\frac{\partial q}{\partial x} = z \cdot 1\\ \frac{\partial f}{\partial y} &= \frac{\partial f}{\partial q}\frac{\partial q}{\partial y} = z \cdot 1\\ \frac{\partial f}{\partial z} &= q \end{aligned} $$
# set some inputs
x = -2; y = 5; z = -4
# perform the forward pass
q = x + y # q = 3
f = q * z # f becomes -12
# perform the backward pass (back prop)
# in reverse order:
# first backprop through f = q * z
dfdz = q # = 3
dfdq = z # = -4
# now backprop through q = x + y
dfdx = 1.0 * dfdq # = -4, dq/dx = 1
dfdy = 1.0 * dfdq # = -4, dq/dy = 1
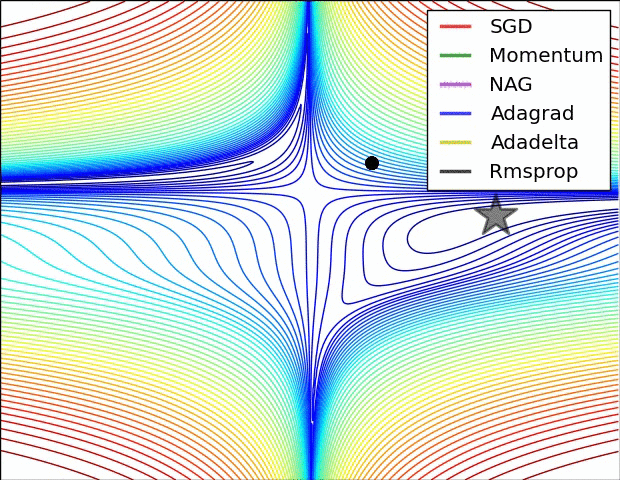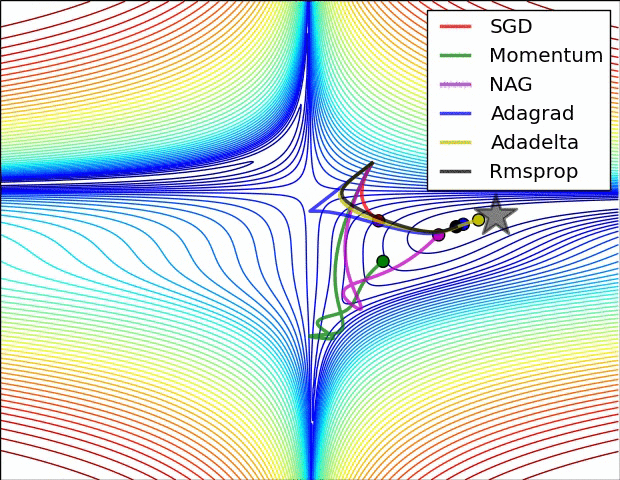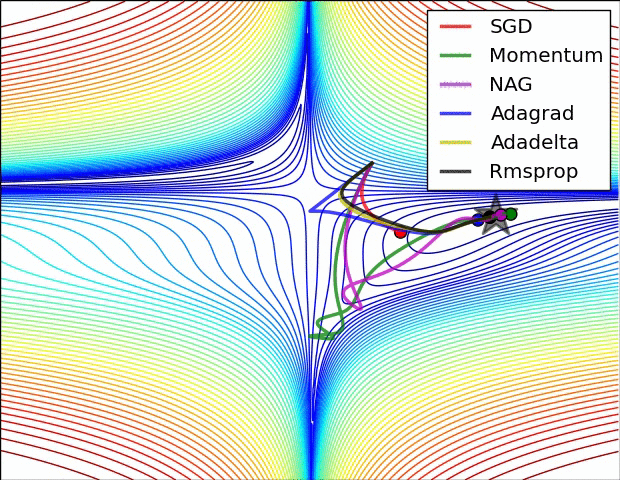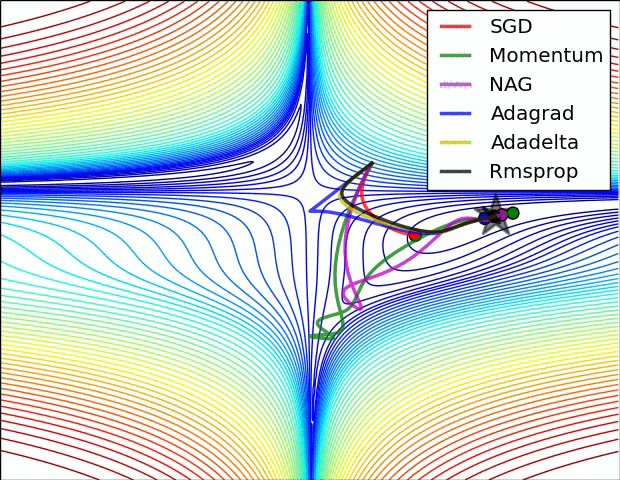
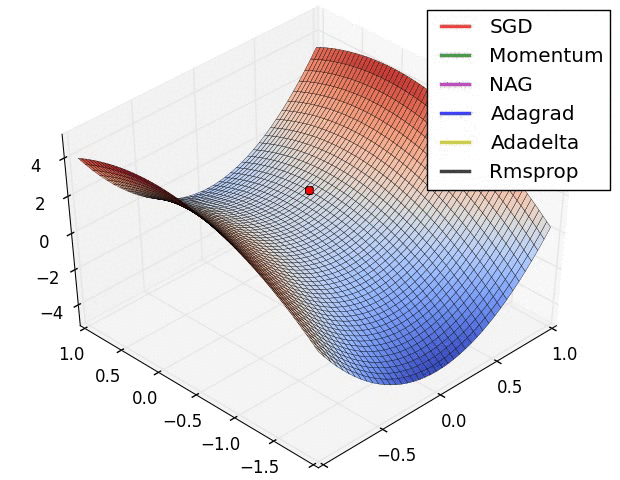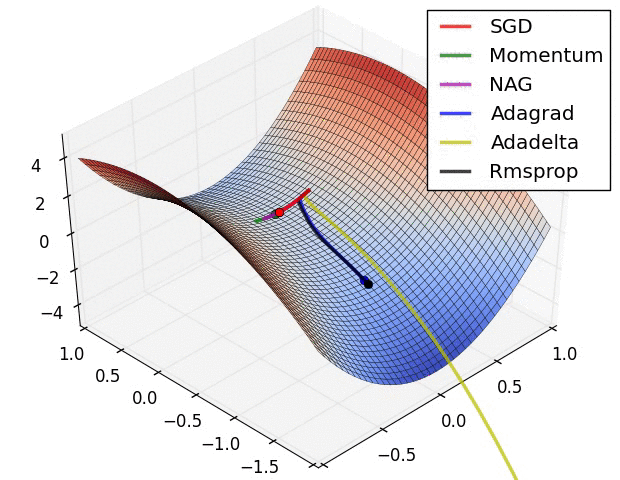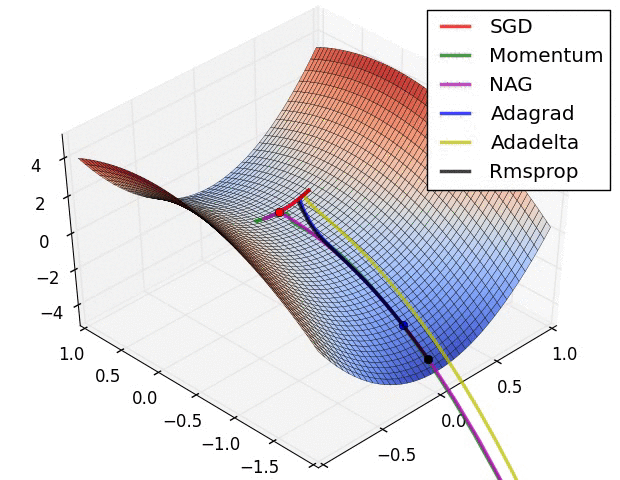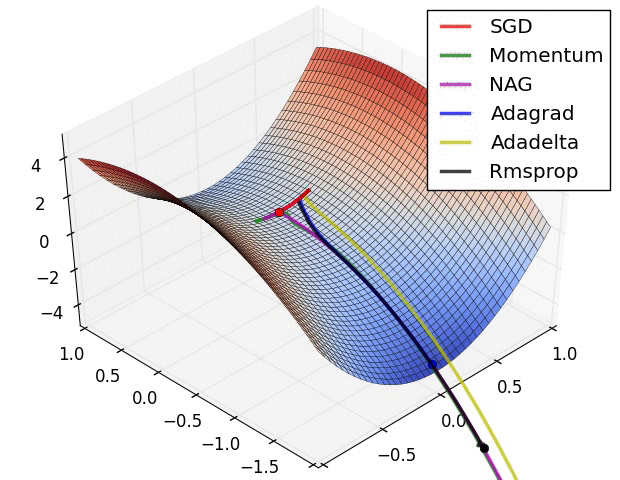
Animations that may help your intuitions about the learning process dynamics. Left: Contours of a loss surface and time evolution of different optimization algorithms. Notice the "overshooting" behavior of momentum-based methods, which make the optimization look like a ball rolling down the hill. Right: A visualization of a saddle point in the optimization landscape, where the curvature along different dimension has different signs (one dimension curves up and another down). Notice that SGD has a very hard time breaking symmetry and gets stuck on the top. Conversely, algorithms such as RMSprop will see very low gradients in the saddle direction. Tue to the denominator term in the RMSprop update, this will increase the effective learning rate along this direction, helping RMSProp proceed.
Ref: CS231n Note: Neural Network 3 and Image credit: Alec Radford.
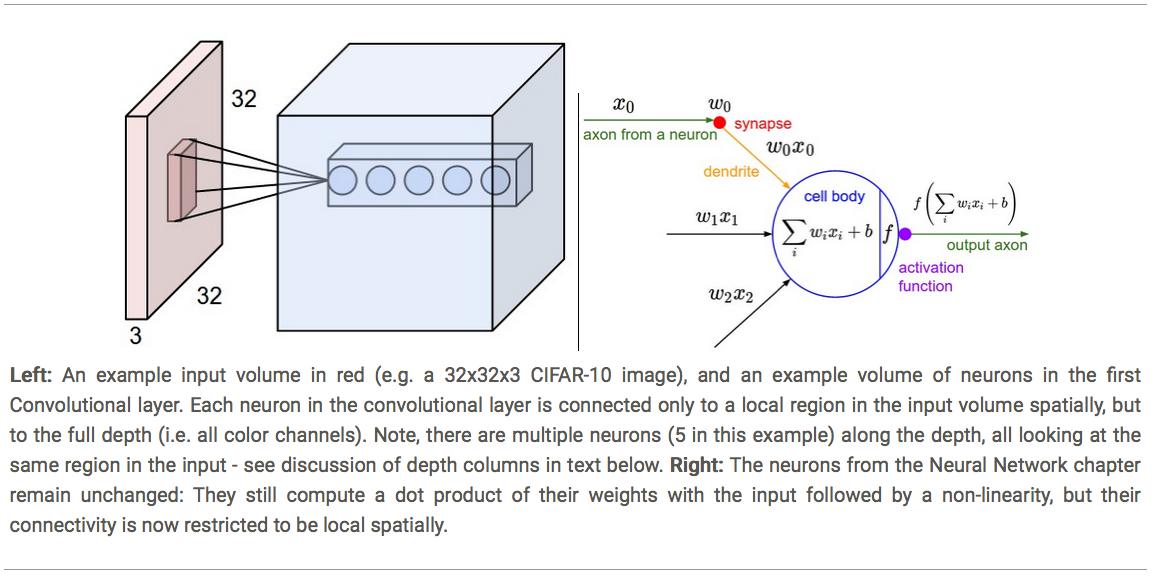
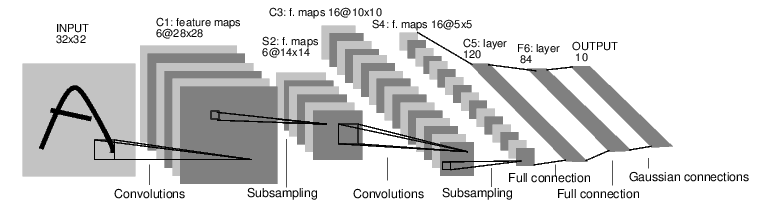
Input viewed as 32 width x 32 height x 3 channels (depth)
Output viewed as 1 x 1 x 10. Spatial information is preserved.
Receptive field: height and width of the spatially bounded input of all depths the neuron next stage takes from the former layer.